
pydictor 工具的妙用
0x01 前言
感觉这个工具还可以,在这里学习一下用法
0x01 场景
去除重复项
面对合并后的超大字典,还是不舍得只要频率高的词,路径字典有时候还是多多益善。去重下,照单全收
1 | python3 pydictor.py -tool uniqifer uniq.txt --output 1.txt |
或者直接合并加去重
1 | python3 pydictor.py -tool uniqbiner /path --output uniq.txt |
字典合并
字典都不是凭空捏造或生成的,一般都会参考前辈们公布的字典。所以,先收集百八十个字典,放到一个目录下,把字典合并起来吧。
-
合并目录/网站路径爆破字典
-
合并子域名字典
-
合并用户名字典
-
合并弱密码字典
-
其它各式各样的字典
1 | python3 pydictor.py -tool combiner /my/dict/dirpath -o comb.txt |
词频统计
但是有时候我们通常不需要那么大的字典,选合并后字典的出现频率最高的前1000条保存吧。筛选出最常用的网站路径/子域名/用户名/弱密码/…
修改 lib/data/data.py 中 counter_split 变量指定的分隔符 ( 默认 “\n” ),也可以统计其它字符分隔的字典词频.
1 | python3 pydictor.py -tool counter vs 222.txt 100 |
枚举数字字典
准备好字典了,拿最基础的试试手
1.爆破 4 位或 6 位数字手机短信验证码
2.爆破用户名ID值
生成 4 位纯数字字典
1 | python pydictor.py -base d --len 4 4 |
简单用户名字典
不能确定是否存在某用户时,试试 1 位到 3 位的拼音字典,加上 123456 这样的几个弱口令,说不定就有意外收获:
1 | python pydictor.py -base L --len 1 3 -o dict.txt |
后台管理员密码字典(明文传输)
经常遇到的测试场景了,就是一个登录页,把收集到的信息都用上,生成后台爆破字典,比如
域名: test.land.com.cn
编辑名: 张美丽、Adaor、midato
公司名: 上海美丽大米有限责任公司(如有雷同纯属巧合)
座机: 568456
地址: xxx 园区 A 座 312 室
把自己常用的弱口令字典复制到 wordlist/Web 目录下,最终生成的字典会包含它们;
然后把下列信息写入 /data.txt
1 | test |
生成字典
1 | python pydictor.py -extend /data.txt --level 3 --len 4 16 |
后台管理员密码字典(前台普通加密)
有时候网站的密码可能不是直接明文传输过去的,程序员会用 js 简单加密下再传输过去,比如 base64 编码、md5 加密,这时候可以用 --encode 参数生成加密字典
1 | python pydictor.py -extend /data.txt --level 3 --len 4 16 --encode b64 |
1 | python pydictor.py -extend /data.txt --level 3 --len 4 16 --encode md5 |
后台管理员密码字典(前台js自定义加密)
高级点的程序员,还喜欢前端自定义个 js 加密方法,把用户名和密码加密后传输过去,比如
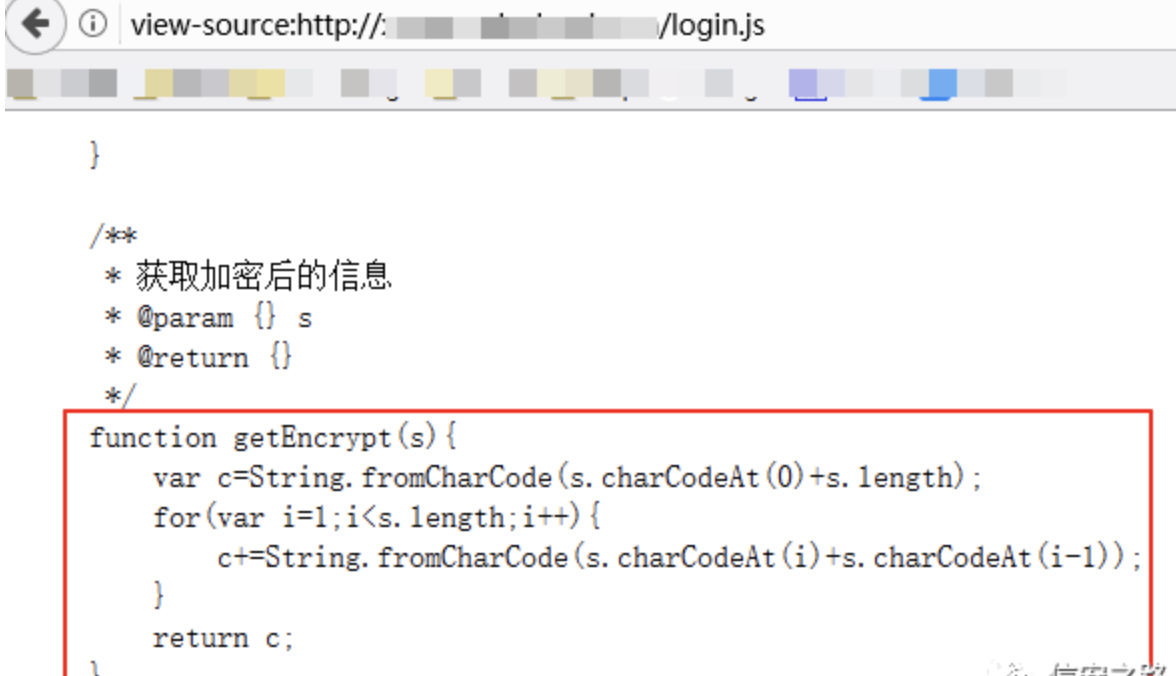
这时候,普通爆破工具基本都无能为力了,但是却依旧可以通过 pydictor 来生成字典;
修改 /lib/fun/encode.py 文件的 test_encode() 函数,用 python 语法仿照上图的加密方式再实现一遍加密:
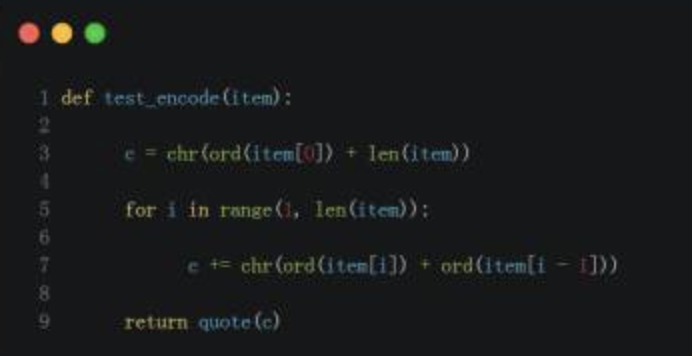
然后运行命令,生成按照前端js加密方法加密后的密码字典,可以直接用burpsuite加载
1 | python3 pydictor.py -extend /data.txt --level 3 --len 4 16 --encode test |
需要注意的是,一般生成加密字典前要生成一个没加密的字典,因为每一项在文件中的顺序是一致的,所以爆破出来密码后,可以通过行数对照去没加密的字典中查找明文。
